Face shape classification
Roadmap
- Face shape classification
- getYourLook WebApp
Inspiration
I have found an interesting paper1 with a SOTA approach to classify face shapes.
Face shape classification has numerous applications in fields such as beauty industry, plastic surgery, security, entertainment industry, and others. For example, in the beauty industry, knowledge of a person’s face shape can be used to recommend makeup products and application techniques that will complement their features, to recommend hairstyles, glasses frames or hats.
So I decided to implement my classifier based on this paper.
Preprocessing
For training the neural network I used the same dataset2 as in paper1, which consists of 4998 images of female celebrities categorized according to their face shape. There are five face shape classes: Heart(999 images), Oblong(999 images), Oval(1000 images), Round(1000 images) and Square (1000 images).
The preprocessing method includes three stages:
- face detection - get a face area bounding box
- face cropping - the face area is cropped into a square face image
- image scaling - all the cropped images are resized to 150px x 150px, which is the input size for the neural network (in my implementation this stage goes during loading of the dataset)
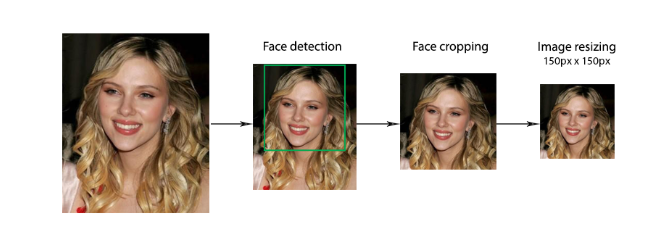
The goal of this is to achieve better classification performance with elimination of background and other noise in an image.
In the paper, face detection is performed using HOG and Linear SVM on all images in the dataset. But that face detector was unable to detect faces in some of the images.
I used a Multi-task CNN3 face detector that successfully detected faces in all images.
Data augmentation
The augmentation method increases the number of images in the dataset while making it more difficult for the network to learn, because none of the images are completely standard. With OpenCV I implemented all variants from the paper1:
- image rotation for a value between -50◦ and 30◦
- adding Gaussian noise to an image
- horizontal image mirroring
- changing the contrast of an image for gamma value of 2

Load dataset
In order to implement the proposed approach, a holdout method was used. The dataset was split into a train (80%) and test (20%) set. The train set was further split into train (80%) and validation (20%) set. While loading images were rescaled:
IMAGE_RES = 150
BATCH_SIZE = 16
train_ds, valid_ds = keras.utils.image_dataset_from_directory(
"augmented_ds/train/",
labels="inferred",
label_mode="int",
batch_size=BATCH_SIZE,
image_size=(IMAGE_RES, IMAGE_RES),
validation_split=0.2,
seed=121,
subset="both"
)
test_ds = keras.utils.image_dataset_from_directory(
"augmented_ds/test/",
labels="inferred",
label_mode="int",
batch_size=BATCH_SIZE,
image_size=(IMAGE_RES, IMAGE_RES)
)Create model and use transfer learning
I used the proposed in the paper1 method - took EfficientNetV2S and fine tuned it.
EfficientNetV2S model architecture:
| Stage | Operator | Stride | Channels | Layers |
|---|---|---|---|---|
| 0 | Conv3x3 | 2 | 24 | 1 |
| 1 | Fused-MBConv1, k3x3 | 1 | 24 | 2 |
| 2 | Fused-MBConv4, k3x3 | 2 | 48 | 4 |
| 3 | Fused-MBConv4, k3x3 | 2 | 64 | 4 |
| 4 | MBConv4, k3x3, SE0.25 | 2 | 128 | 6 |
| 5 | MBConv6, k3x3, SE0.25 | 1 | 160 | 9 |
| 6 | MBConv6, k3x3, SE0.25 | 2 | 256 | 15 |
| 7 | Conv1x1 & Pooling & FC | - | 1280 | 1 |
My model:
- base model - I downloaded EfficientNetV2S with pretrained on Imagenet weights as a base model but without the top layer and with avarage pooling on the top. The base model contains batchnorm layers, so to keep weights from going wild the base_model is running in inference mode. For initital fit the base model is frozen
- top layer - on the top I added dense layer with 5 neurons (number of face shape classes) and softmax activation function
- optimizer - Adam optimizer with 0.0001 learning rate
- loss - Sparse Categorical Crossentropy Loss
- metrics - Sparse Categorical Accuracy
Model fitting and fine-tuning
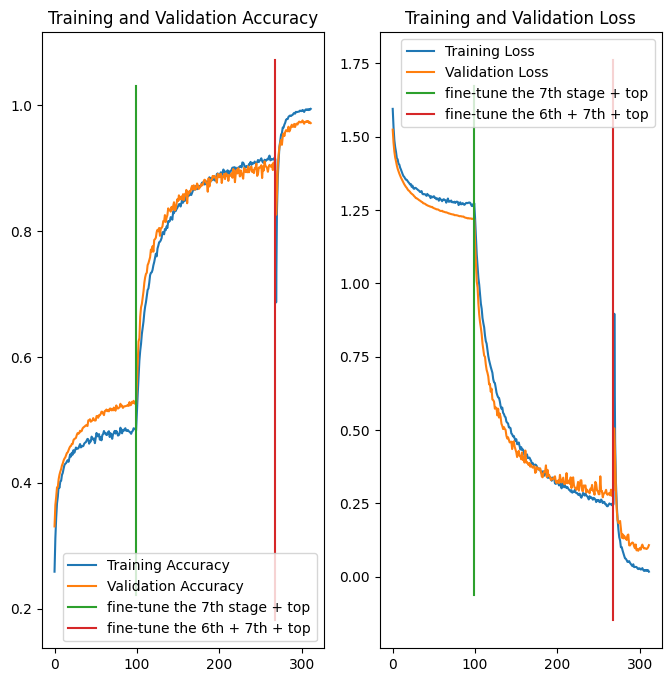
I trained this model in three stages:
- initial fit - the base model is frozen, only the top dense layer is trained for 100 epochs and the best weights are saved. Test accuracy is 0.5282, loss is 1.2078
- fine tune the 7th stage - unfreeze the 7th stage of the EfficientNetV2S and trained it for 169 epochs. Test accuracy is 0.903, loss is 0.2863
- fine tune the 6th and the 7th stages - unfreeze the 6th and the 7th stages of the EfficientNetV2S and trained it for 43 epochs. Test accuracy is 0.9736, loss is 0.0973
Prediction

Then I used this trained model to make a MVP : getYourLook WebApp
-
Grd P, Tomičić I, Barčić E (2024) Transfer Learning with EfficientNetV2S for Automatic Face Shape Classification. JUCS - Journal of Universal Computer Science 30(2): 153-178. ↩ ↩2 ↩3 ↩4
-
(Implementation) Zhang, K., Zhang, Z., Li, Z., and Qiao, Y. (2016). Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Processing Letters, 23(10):1499–1503. ↩